Progressive Music Generation: A Human and Machine Perspective
Human composers and songwriters often use a progressive approach when writing music. This involves starting with a simple idea, such as a single bar of music, and gradually building on it to create a complete piece. They may then expand this idea into a phrase, which is longer than a single bar but shorter than a full section. Once they have several phrases, they can start to piece them together to create sections, such as a verse or a chorus. Finally, they can arrange these sections into a full piece of music, making sure that each section flows smoothly into the next.
Machines can also mimic this progressive approach to automatic music generation tasks. After training the model, a single bar of music can be generated by providing it with a seed sequence of musical data, such as a single note or a short melody. This generated bar can then be expanded into a complete phrase by feeding it back into the model along with additional seed data. With a few phrases generated, they can be pieced together to form a larger section of music. Finally, using the generated sections, a full piece of music can be created by experimenting with different ways of combining the sections, such as repeating or varying certain phrases.
In terms of encoding the musical data for use with a Transformer model, different sequence lengths can be used for different levels of musical structure. For example, a sequence length of one or two notes can be used for encoding individual bars, a sequence length of 4-8 bars for encoding phrases, and a longer sequence length for encoding sections or full pieces of music. This allows the model to learn patterns and relationships at different levels of musical structure and generate music that is coherent and meaningful.
Adopting the idea of text generation in music generation tasks can potentially lead to breakthroughs in generating coherent and creative music pieces. In 2020, Tan et al. [1] proposes a simple yet effective method of generating text in a progressive manner, inspired by generating images from low to high resolution. This approach generates domain-specific content keywords and then progressively refines them into complete passages in multiple stages. By taking advantage of pretrained language models at each stage, the approach can effectively adapt to any target domain given only a small set of examples.
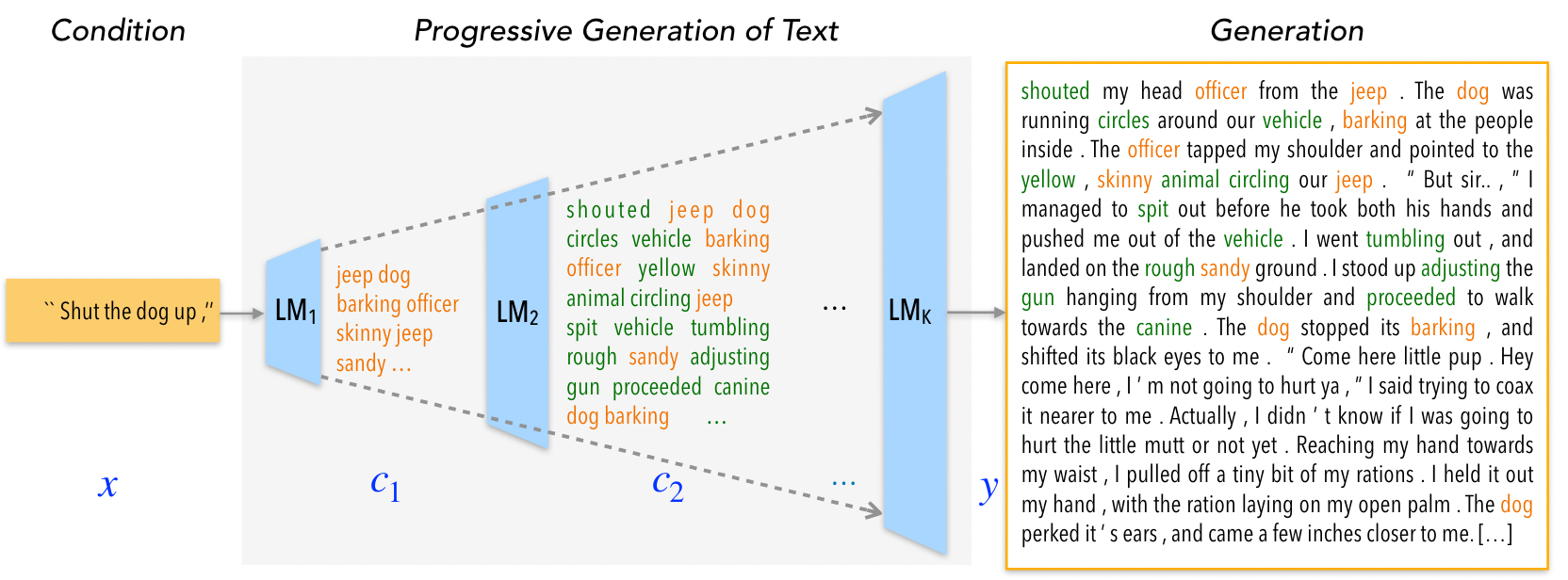
Figure 1: Progressive generation of long text y given any condition x [1]
This method can potentially be applied to music generation tasks, where the progressive generation can be used to generate different components of a music piece, such as the melody, harmony, and rhythm, in multiple stages. The approach can also help overcome the limitations of current music generation models, which often lack coherence and creativity in generating long and complex music pieces. With further research and development, the adoption of text generation techniques in music generation tasks can pave the way for more sophisticated and intelligent music generation systems.
In conclusion, the progressive approach to music generation can be possibly used by both humans and machines. By starting with a simple idea and gradually building on it, composers and machine learning models can create cohesive and interesting pieces of music. With the help of machine learning models, even those without formal music training can experiment with generating music and exploring their creative side.
References:
[1] B. Tan, Z. Yang, M. AI-Shedivat, E. P. Xing, and Z. Hu, “Progressive Generation of Long Text with Pretrained Language Models.” arXiv, Apr. 14, 2021. Accessed: Mar. 19, 2023. [Online]. Available: http://arxiv.org/abs/2006.15720